技术应用
从实际部署情况来看,对于大多数计算和存储而言,所有类型的计算机内存都会有一个上限。在现代计算系统中,内存比其他资源更容易遇到上限,因为操作系统、应用程序和存储总是需要内存。由于不存在无限的内存,所以内存可能会在某个时候被消耗完,这会导致系统不稳定或数据丢失。

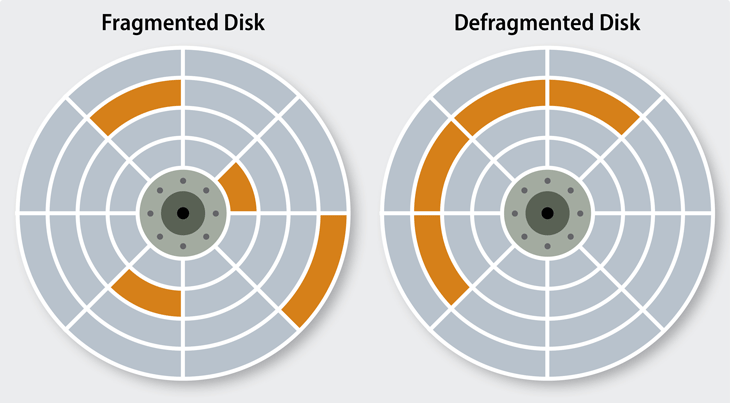
从计算机存储出现以来,磁盘碎片和RAM碎片一直是大家关注的问题。碎片并不总是坏事,因为它在某些操作系统的工作方式中具有特定的用途。不过,它也可能成为整体存储效率的一个阻碍。
Kubernetes是Google开源的一个容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。对于那些工作负载多样化、不断变化的企业来说,使用Kubernetes是非常有利的。

随着大数据与人工智能技术的应用普及,海量多源异构数据急剧增加。传统大数据平台在面临多源异构数据处理时,面临数据采集处理能力不足、数据结构难以统一,数据运维困难等挑战,为企业探索数据价值带来了层层阻碍。


Apache Spark是一种常见的数据处理引擎,用于对超大数据集进行高级分析。在当今涉及基于云的服务、物联网和机器学习的企业用例中,这类数据已经司空见惯。Spark 采用了一个通用的集群计算框架,能够获取和处理实时的超大数据流,即时处理和分析事件和异常情况,

云计算、大数据、人工智能等技术的广泛应用,使数据开始呈指数级增长。在海量数据时代,传统存储系统已难以满足业务运行需求,分布式存储大放异彩,发展迅速。但对于许多企业来说,提高存储系统的并发性能仍然是一大挑战,此外系统稳定性、灵活扩展能力、整合异构存储资源的能力、

人工智能 (AI)是对现代社会的各个领域带来重大影响的技术,这些领域包括电子商务、自然语言翻译、金融科技、安全、目标识别/检测乃至可快速确认危及生命癌细胞位置(或其他异常症状)的医学领域。

过去十年间,浏览器厂商和web性能专家大部分时间都在说本地存储(localStorage)很慢,web开发人员不应该再使用它了。公平地说,说这话的人没有错。本地存储是一个同步API,它会阻塞主线程,任何时候访问它都会潜在地阻止页面的交互。问题是本地存储API非

今天主要来讲下前端的数据存储,说起数据存储,大家肯定第一时间想起cookie,localstorage,sessionstorage,而其实还有userData和IndexedDB这两种数据存储,接下来将对它们进行一个比较详细的总结

在传统的Web中,用户数据存储在自己能够完全控制的集中式存储服务器上。这种控制能力,为他们提供了在用户不知情或未经用户同意的情况下可能会滥用的高级特特权。此外,集中存储可能存在可用性问题,尤其是如果数据仅存储在一个位置时,会因此产生单点故障。

如我们所知,与传统硬盘驱动器(HDD)相比,固态硬盘具有极高的磁盘性能,尤其是新出厂的硬盘。但随着时间的推移,SSD的性能会急剧下降。而且当存储在其上的数据达到总容量的约70%时,尤其如此。SSD测试工具在监控固态硬盘的运行状况和性能方面发挥着重要作用,使用这

NVMe是固态存储时代的下一个阶段,它提高了SSD和网络上其他存储设备的性能。如今,越来越多的服务器开始支持NVMe,IT人员是时候考虑Swap分区(交换区)的使用问题,来最大限度地利用这些系统了。

NVMe通过改进物理接口、增加命令数量和队列深度,使存储基础设施能够充分利用闪存的优势。但是NVMe也带来了一个挑战:NVMe的延迟非常低,它暴露了存储基础架构中其他组件的弱点。基础架构中的任何薄弱环节都会增加延迟并降低NVMe的价值。

RAID最初是廉价磁盘冗余阵列(Redundant Array of Inexpensive Disks)的缩写。如今,这个名词的含义已更新为独立磁盘冗余阵列(Redundant Array of Independent Disks),但是它的最终目的并没有改

数据分布不平衡是机器学习工作流中的一个重要问题。所谓不平衡的数据集,意思就是两个类中一个类的实例比另一个要高,换句话说,在一个分类数据集之中,所有类的观察值的数量是不一样的。这个问题不仅存在于二进制类数据中,也存在于多类数据中。

可以说,容器化彻底改变了我们对应用程序开发的思考方式,它带来很多好处:开发和生产之间的一致环境、使用共享的资源但容器之间相互隔离、云环境之间的可移植性、快速部署……等等不胜枚举。容器所固有的短暂性是它之所以伟大的核心原因:不可变的、相同的容器,可以在一瞬间快速

什么是无服务器存储/无服务器数据库?它与其他的存储/数据库服务有什么不同?这篇文章将介绍无服务器存储服务应具有的基本属性,并通过无服务器计算中的一些用例,举例说明不同的无服务器存储和无服务器数据库类别之间的区别。最后,我们将继续讨论尚未出现的无服务器存储服务类

保证业务连续性,是灾难恢复(DR)计划的主要目标。更具体一点说,灾难恢复意味着企业需要获得有意义、有价值的RPO(恢复点目标)和RTO(恢复时间目标)服务等级协议,以便在遇到灾难后,尽快恢复关键业务应用。
