Google DeepMind 最新研究:搞定这三个任务?人类不行,AI 也不行
撰文 | 赵雅琦
前言
人工智能(AI)并非完美的推理者,即使是当前大热的语言模型(LMs),也同样会表现出与人类类似的错误倾向,尤其是出现显著的“内容效应”(Content effects)——人们在处理与已有知识或信念相符的信息时,推理更加准确和自信,而在处理与这些知识或信念相悖的信息时,推理可能会出现偏差或错误。这一结论来自 Google DeepMind 团队近期发表的一篇研究论文。

人类存在两种推理系统,“直觉系统”和“理性系统”,且在推理过程中容易受到已有知识和经验的影响。例如,当面对合乎逻辑但不合常理的命题时,人们往往会错误地判定其无效。
有趣的是,该研究显示,大型 Transformer 语言模型也可以表现出类似人类的这种行为,既可以展示出直觉性偏见,也可以在提示下表现出一致的逻辑推理。这意味着,语言模型也能模拟人类的双系统行为,也会表现出“经验主义”错误。在这项工作中,研究团队对比了 LMs 和人类分别在自然语言推断(NLI)、判断三段论(Syllogisms)的逻辑有效性和 Wason 选择任务三种推理任务上的表现。

图 | 三种推理任务操作内容结果发现,在三种推理任务中,LMs 和人类的表现均受语义内容合理性和可信度的影响。这一发现揭示了当前 AI 系统在推理能力上的局限性。尽管这些模型在处理自然语言方面表现出色,但在涉及复杂逻辑推理时,仍需谨慎使用。
任务一:
自然语言推理
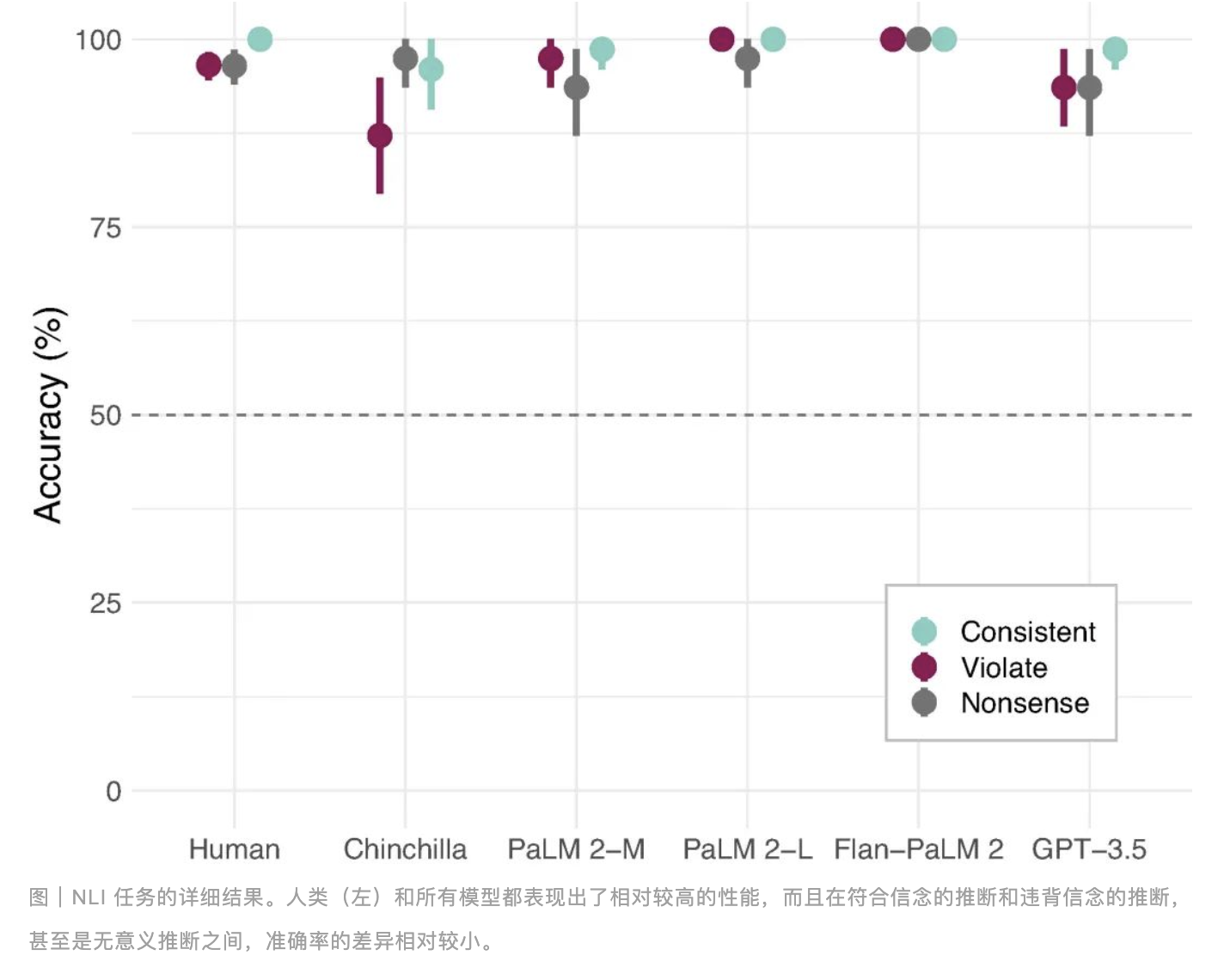
自然语言推断(NLI)是指模型需要判断两个句子之间的逻辑关系(如蕴涵、矛盾或中性)。研究表明,语言模型在这类任务中容易受到内容效应的影响,即当句子的语义内容合理且可信时,模型更容易将无效的论证误判为有效。这一现象在 AI 领域被称为“语义偏见”,也是人类在推理过程中常见的错误。研究团队设计了一系列 NLI 任务,测试人类和 LMs 在处理这些任务时的表现。结果显示,无论是人类还是 LMs ,当面对语义合理的句子时,都更容易出现错误判断。例如,下面这个例子:
输入:水坑比海大。
提问:如果水坑比海大,那么......
选择:A “海比水坑大”和 B “海比水坑小”
虽然前提和结论之间的逻辑关系是错误的,但由于前提句子的合理性,LMs 和人类都容易认为 B 这个结论是正确的。通过对比,人类和语言模型在自然语言推断任务上的错误率相近,表明语言模型在某些方面的推理能力已经接近人类水平,而 AI 在理解和处理日常对话时,可能会与人类一样容易受到内容的误导。
任务二:
三段论的逻辑有效性判断
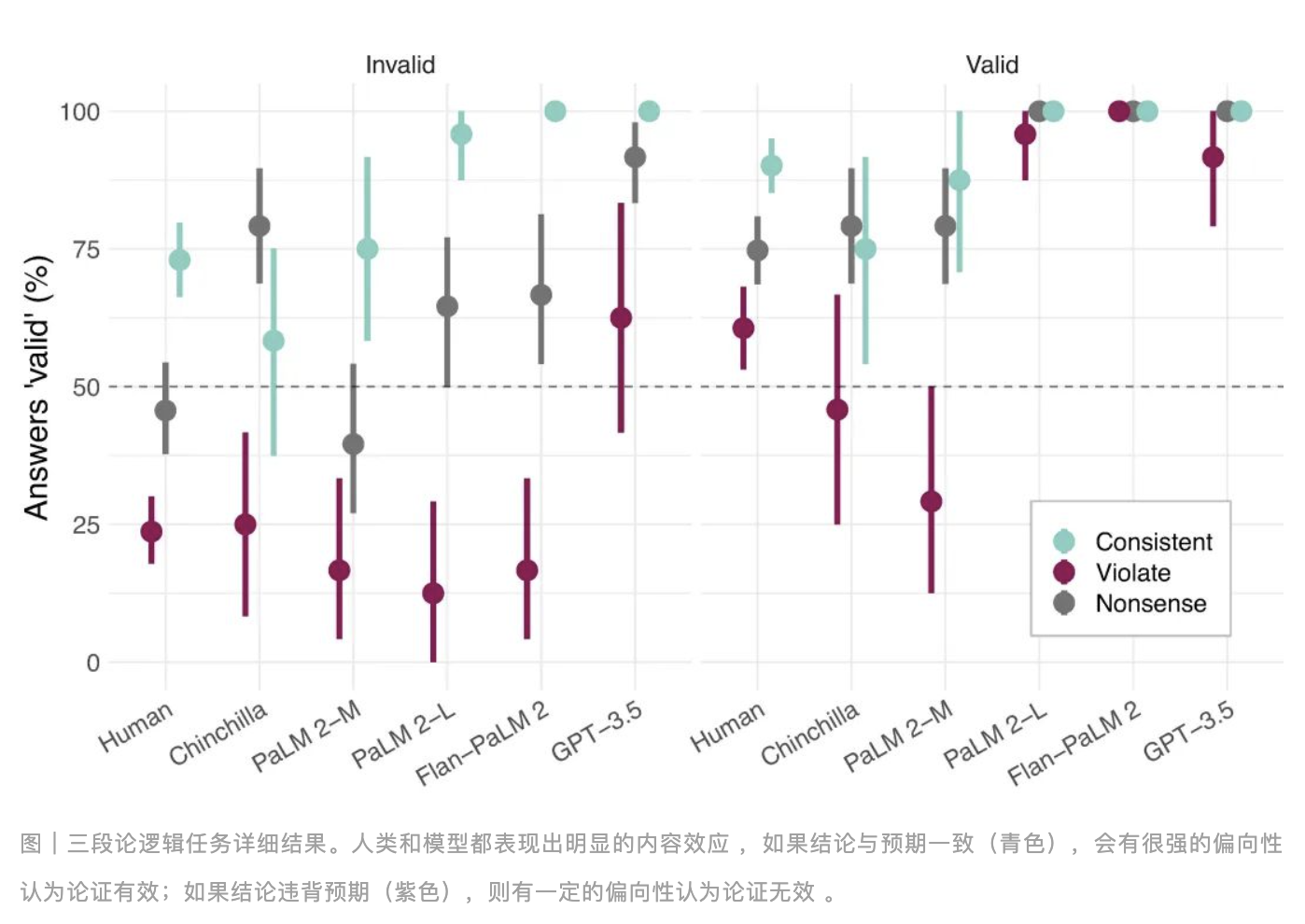
三段论是一种经典的逻辑推理形式,通常由两个前提和一个结论组成。例如:“所有人都是会死的,苏格拉底是人,所以苏格拉底会死。”研究发现,语言模型在判断三段论的逻辑有效性时,常常会受到语义内容的影响。尽管语言模型在处理自然语言方面表现优异,但在严格的逻辑推理任务中,仍然容易犯与人类相似的错误。为了验证这一点,研究人员设计了多个三段论推理任务,并对比了人类和 LMs 的表现。例如,以下是一个典型的三段论任务:
前提 1:所有枪都是武器。
前提 2:所有武器都是危险的物品。
结论:所有枪都是危险的物品。
在这种情况下,前提和结论的语义内容非常合理,因此 LMs 和人类都很容易判断这个结论是正确的。然而,当语义内容不再合理时,例如:
前提 1:所有危险的物品都是武器。
前提 2:所有武器都是枪。
结论:所有危险的物品都是枪。
尽管逻辑上是错误的,但由于前提句子的合理性,LMs 和人类有时仍会错误地认为结论是正确的。
任务三:
Wason 选择
Wason 选择任务是一个经典的逻辑推理任务,旨在测试个体对条件语句的理解和验证能力。在实验中,参与者会看到四张卡片,每张卡片上有一个字母或数字,例如“D”、“F”、“3”和“7”。任务是确定哪些卡片需要翻面,从而验证“如果一张卡片正面是 D,那么背面是 3”这一规则。研究发现,语言模型和人类在这一任务和前面两个任务一样,错误率相近,且都容易选择没有信息价值的卡片,例如,选择“3”,而不是“7”。出现这种错误是因为人类和 LMs 都倾向于选择与前提条件直接相关的卡片,而不是那些能真正验证规则的卡片。然而,当任务的规则涉及到社会相关的内容(如饮酒年龄和饮料类型)时,模型和人类的表现都会有所改善。例如:
规则:如果一个人喝酒,他必须超过 18 岁。
卡片内容:喝啤酒、喝可乐、16 岁、20 岁。
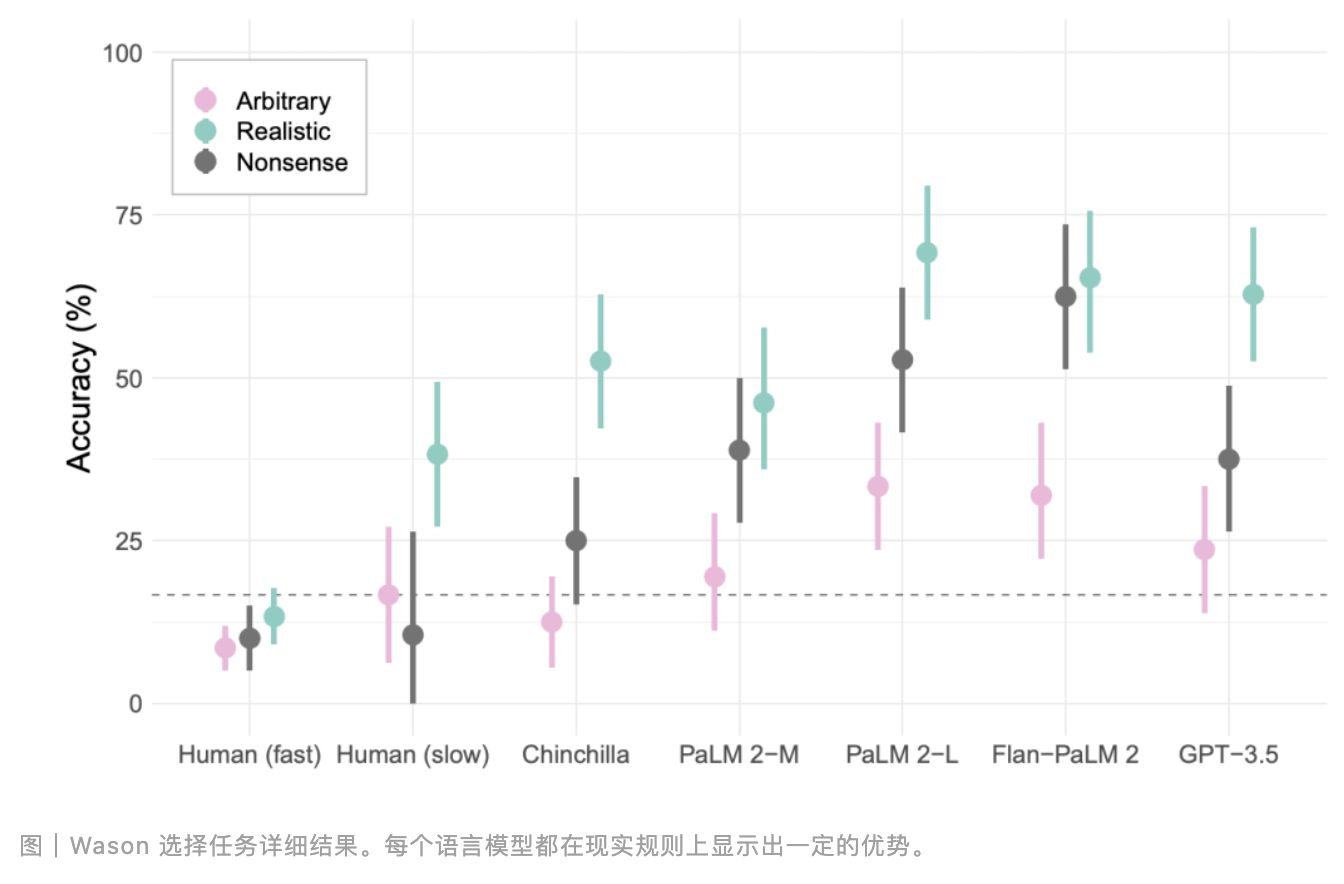
在这种情况下,人类和 LMs 更容易选择正确的卡片,即“喝啤酒”和“16 岁”。这表明,在日常生活中,AI 与人类一样,会在熟悉的情境中表现得更好。
不足与展望
总的来说,研究团队认为,当下的语言模型在推理任务方面与人类表现相差不多,甚至犯错的方式也如出一辙,特别是在涉及语义内容的推理任务中。虽然显露出了语言模型的局限性,但同时也为未来改进 AI 推理能力提供了方向。然而,这项研究也存在一定的局限性。首先,研究团队仅考虑了少数几个任务,这限制了对人类和语言模型在不同任务中的内容效应的全面理解。要完全理解它们的相似性和差异性,还需要在更广泛的任务范围内进行进一步验证。另外,语言模型接受的语言数据训练量远远超过任何人类,这使得难以确定这些效应是否会在更接近人类语言数据规模的情况下出现。研究人员建议,未来的研究可以探索如何通过因果操纵模型训练来减少内容偏见,并评估这些偏见是否在更类似人类数据规模的训练中仍会出现。此外,研究教育因素对模型推理能力的影响,以及不同训练特征如何影响内容效应的出现,也将有助于进一步理解语言模型和人类在推理过程中的相似性和差异,使其在更广泛的应用场景中发挥更大的作用。
论文链接:
https://academic.oup.com/pnasnexus/article/3/7/pgae233/7712372

