【作者】韩锋,CCIA(中国计算机协会)常务理事,前Oracle ACE,腾讯TVP,阿里云MVP,dbaplus等多家社群创始人或专家团成员。有着丰富的一线数据库架构、软件研发、产品设计、团队管理经验。曾担任多家公司首席DBA、数据库架构师等职。在云、电商、金融、互联网等行业均有涉猎,精通多种关系型数据库,对NoSQL及大数据相关技术也有涉足,实践经验丰富。曾著有数据库相关著作《SQL优化最佳实践》、《数据库高效优化》。
近日参加金融行业数据库使用交流,大家讨论热点问题之一就是分布式数据库的选型问题。近些年来,随着数据规模增加、数据使用复杂度提高,对底层数据库能力要求越来越高,传统集中式数据库已不能满足需要;分布式数据库成为必然的选择。金融行业,作为数据应用的高地,对数据库的要求自然更高。然而面对纷繁复杂的数据库种类,该如何选择呢?本文尝试从分布式数据库的发展路线、技术分类、行业痛点等角度,谈谈分布式数据库的选型问题。
1.分布式数据库演进之路
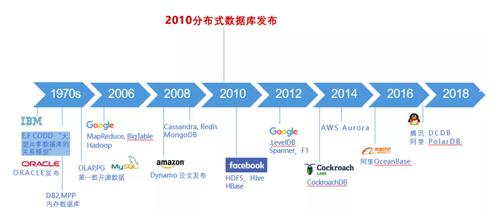
单机型数据库,最早源自上世纪70年代,从IBM著名的论文开始,后面诞生了Oracle、DB2为代表的优秀商业产品以及PostgreSQL、MySQL为代表的开源产品。这些产品很好的满足了对数据存储和计算的需求。
随着21世纪初期,互联网浪潮的来临,数据规模呈爆炸式增长,单机数据库越来越难以满足用户需求。这也催生了分布式数据库的到来。到了2006年之后,出现以 HBase/Cassadra/MongoDB为代表的NoSQL类产品。这些产品实现了分布式架构,可以实现容量的水平扩展,但也牺牲了诸如事务、SQL访问接口等能力。存储模型的简化为存储系统的开发带来了便利,但是降低了对业务的支撑。在这一阶段,很多企业为了解决大规模数据存储与访问的问题,也研发了很多中间件产品。其原理是通过将数据分片存储到单机库,上层对SQL解析实现对语句的路由。这种方式有一定的难点,例如对分布式事务的处理及规模扩大下的管理问题。
到了2012年,Google的论文为关系模型的分布式架构,提供了新型分布式数据库理论基础。在此之后,诞生了一系列新型分布式数据库产品。其原理是通过分布式一致性算法协议完成底层数据多副本存储,上层则实现了标准SQL支持能力。
分布式数据库之辩
从上文可看到分布式数据库的发展非常之快,目前仍处于高速发展期;而且并不是单一发展路径,有很多技术路线同步发展。因而,大家口中的“分布式数据库”可能代表的技术栈完全不同。下图尝试对常见的“分布式数据库”产品按技术实现差异做个简单分类。下述分类仅代表个人观点,部分产品因技术快速演进可能有所变化。
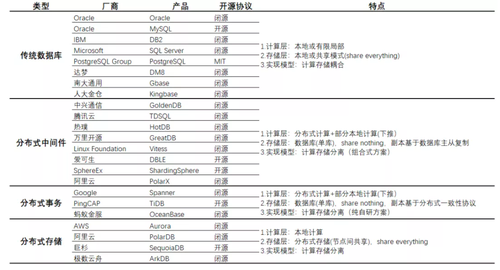
除了传统数据库外,这里将分布式数据库分为三种情况:
- 分布式中间件
这种架构是从之前谈到的中间件路线演进而来。其采用存储与计算分离架构,底层采用标准单机数据库,副本间基于数据库主从复制机制。上层承担计算,并可将部分计算下推到存储节点执行。这种架构在分布式事务、全局MVCC等方面,往往存在一定难点,各厂商也有各自解决之道。
- 分布式事务
这种架构正是受到Google论文影响演进而来。其采用存储与计算分离架构,底层采用单机库(不一定是关系型),副本间采用分布式一致性协议完成复制,支持多数派提交。上层承担计算,并可将部分计算下推到存储节点执行。
- 分布式存储
这种架构另辟蹊径,其上层是采用本地计算方式,下层采用分布式存储,节点间共享数据。这种架构需要严格依赖于底层存储系统。
典型产品示例(分布式中间件)
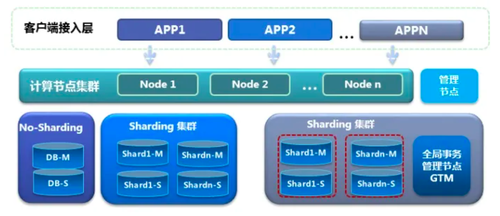
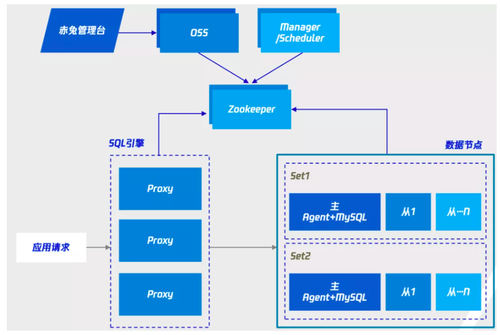
上图一摘自GoldenDB数据库,上图二摘自TDSQL数据库。从上面两图可见,此类数据库架构大致都分为几个组件:
计算节点(或称Proxy)集群,由一组无状态节点组成,响应用户请求、解析SQL、完成逻辑优化、物理优化,生成分布式执行计划,下发到数据节点,完成用户操作请求。
数据节点集群,真正完成数据存储功能。集群由若干单元组成,数据按分片策略存储在单元中。每个单元内由一组独立数据库主从集群构成,实现对数据的高可用保证。
管理节点(含配置中心),负责集群组件管理、元信息存储等,不涉及业务访问流程。
事务管理器((G)TM),负责事务管理,有中心化或非中心化不同实现策略。
管理控制台,负责集群管理、维护职能。
典型产品示例(分布式事务)
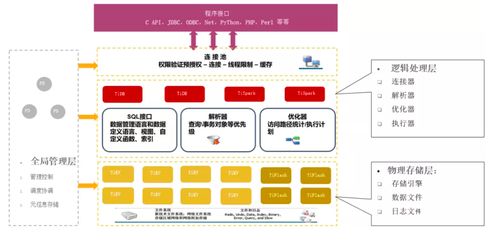
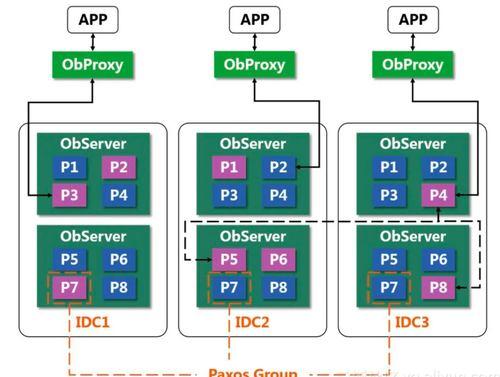
上图一摘自PingCAP-TiDB数据库,上图二摘自Oceanbase数据库。此类分布式数据库的实现差异是较大的,不同厂商有各自的实现策略。前者倾向于中心化实现,后者倾向去中心化。但总体上,还是包含两类组件,一是计算节点、二是存储节点。前者实现了用户访问接入,后者通过分布式一致性算法,实现数据的多副本存储。
2.数据库选型的痛点与难点
如之前所说,金融行业正面对底层基础设施的转型问题,数据库作为重要的底层技术栈同样面临一个选择的问题。但在这一选择过程中,往往存在较多的痛点和难点。这主要是因为金融行业的特殊性所造成的。
【痛点】基础功能待完善
对标传统集中式数据库,现有的分布式数据库在功能上仍然有待完善。这一方面是因为分布式架构所造成的功能tradeoff,另一方面是在产品化能力完整性上的欠缺。前者是我们在使用分布式数据库产品时,需要在架构、设计层面需要在关注的,在项目初期都需要解决掉的。而后者厂商产品经过多年发展在内核能力上已趋于完善,但在周边配套的管理、设计、优化工具上,仍需进一步完善。毕竟最终为用户呈现的,是一套完整的数据库解决方案。
【痛点】运行稳定待验证
对于金融行业而言,稳定性是第一位的。虽然分布式数据库在设计之处,就将稳定性设计放在优先位置,其天然的分布式架构也有利于提供更高的可用性保证。但一方面分布式架构天然由多组件组成,其复杂程度较集中式更高;另一方面其对底层基础环境的要求也更高。此外,产品的稳定性是要在长期实践中不断打磨、持续改进的。分布式数据库作为后来者,也需要经历这一过程。
【痛点】迁移改造任务重
选择使用分布式数据库产品,对应用侧来说,需要有大量的应用迁移工作。一方面是由于分布式数据库较集中式数据库功能上有所削弱,另一方面更换数据库天然所需要的移植工作。虽然目前各分布式数据库也推出xx兼容能力,但从实际效果来看仅能减少部分移植工作,整体迁移任务量仍然很高。且迁移采用所谓的兼容模式,也不利于后期平滑更换,这点后面会讲到。
【痛点】风险巨大需并行
对底层数据库的更换,是存在较大技术风险的。一是由于新产品、新架构所带来的风险;二是应用迁移改造带来的不确定性;三是产品本身的稳定性的潜在风险。为应对这种情况,最为稳妥的方式是采取应用双发并行的方式解决。这种方式可在最大程度上减少可能初期的风险,可做到数据冗余、无缝切换、灵活可控等,但其花费的代价也是非常高的。需要从应用端做大量双发改造,如果更换系统很多,这方面代价是比较大的。
【难点】生态环境需培育
虽然发展多年,但国产分布式数据库在整体市场上仍然属于小众选择。之前国外厂商产品占据市场领导地位,经过多年发展已形成了较为完善的生态。随着近些年来,MySQL、PG开源数据库在互联网行业得到大量应用,积累大量用户,建立其不错的生态。很多国产分布式数据库采用迂回策略,通过兼容上述数据库标准,来享受开源生态红利。此外,近期国产数据库如TiDB、OB、PorlaDB、openGuass等,也纷纷开源建设自有生态。
【难点】信创要求时间紧
作为国家安全的重要举措之一,安全可控成为基础要求,信创因而诞生。为保证上述政策执行到位,国家也设定实施计划。作为基础软件的数据库,也是信创工作的重点。如何在规定的时间内完成,也为各企业带来的很大压力。
【难点】场景多元难选择
与互联网企业不同,金融行业对数据的使用场景更加多元化,这也对数据库提出了较高的要求。仅选择单一数据库满足全场景需求,几乎是不可能的。在传统集中式数据库上,这一问题还不明显,因为这些数据库往往是多面手,各方面功能较为均衡;而分布式数据库则不然,其往往有明确的适用场景范围。而作为企业用户,是需要对自己场景有个清晰的认识,然后按图索骥找到适合自己的产品,例如下图。
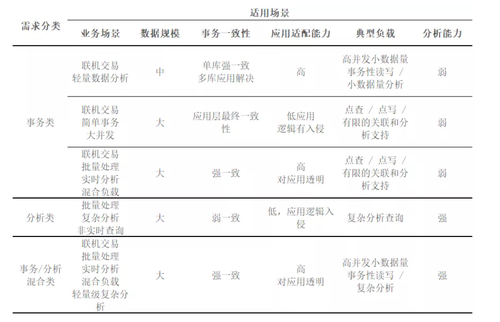
【难点】厂商绑定风险高
选择某厂商产品,也就意味着选择某一技术路线,如果深度依赖厂商产品的特有能力,无疑存在绑定风险问题。这点对于分布式数据库来说,表现尤甚。各厂商产品实现差异很大,没有通用的使用标准。如何规避这一风险,带来最大的自由度选择?后文会展开说明。
3.数据库选型策略推荐
针对上述诸多难点、痛点,作为金融行业如何选择分布式数据库呢?这谈几点个人的见解。
尊重路线之争,无关技术领先
如前面所述,分布式数据库的发展有着不同的技术路线。曾有种观点认为,“分布式数据库的发展方向代表着未来,分布式中间件方向没有前途”。针对这一问题,我的观点是采用不同技术路线的产品有自己的适用场景,与技术领先性无关。某种技术通过提出理论、工程化实现、产品能力输出,可解决某方面需求、甚至带来巨大产品能力的提升;但希望以此通过大一统的产品解决所有问题是不现实的,未来仍然是多种技术路线并存的情况。
成熟度有待完善,但时不我待提前规划
分布式数据库作为一种新兴技术产品,其成熟度尚需锤炼,但不能基于此就选择观望态度。产品成熟的提高,一方面来自厂商对产品的不断迭代优化;另一方面也来自使用者的不断打磨。企业内对数据库的落地使用,也需要较为长期的过程。此外,外部驱动也对这一选择起到加速推动作用。作为企业来讲,根据自身情况可以选择不同策略(引领、跟随);但无论那种都需要提前规划,有明确方向和实施路径。
国产数据库百花齐放,机会无限
近些年来,国产数据库发展迅猛,呈现百花齐放态势。针对这一现状,一方面要持续关注这些产品,给予这些产品充分施展机会;另一方面制定准入标准严格把关,让真正有实力的厂商能够进入,得到充分锻炼、打磨的机会。
慎重技术选型,不迷信宣传
技术选型是个很严谨的过程,需要慎重对待。有很多第三方的评测和厂商宣传结论,但这些只能做参考,决策层面的依据还是需依靠自己。一方面宣传内容一般都会所选择有利于自己,这会带来一定误导性;另一方面对同一概念的理解是有偏差的,很难仅仅通过一段文字描述就能完全说清楚(例如,数据一致性,背后的解读就有很多)。这些问题只有在真实环境,叠加上自身需求,测试出的结果才具说服力。
结合场景需求,没有最好只有最适合
业务场景千差万别,其对数据库能力要求和侧重点也有所不同。很难选择一款通用型产品满足全场景,那就需要根据实际情况做有针对性的选择。此外,不同产品各有强点和局限之处,选择最适合你的产品就好。例如上文谈到的分布式中间件产品,在超大规模、自定义分片、超高性能、业务控制等方面往往更有优势;而分布式数据库产品,则在分布式事务、数据强一致、混合负载等方面有所擅长。
不选产品选兼容性,保持最大自由度
当前分布式数据库,仍然处于快速发展期,很难确定未来的主流选择。为了规避路线选择、厂商绑定的风险,比较现实的方法是选择一款兼容通用性协议的产品,并且在使用中仅使用标准数据库的用法。举个例子,选择一款兼容MySQL的产品并且安装标准MySQL的用法使用;当出现风险时完全可选择另外一款同样兼容MySQL的产品来替代。目前MySQL生态在国内最为成熟,很多厂商产品也选择了兼容它,因此选择兼容性产品在未来的自由度最大。
保持技术敏感度,紧跟时代发展步伐
面对技术发展多变、应用特点多变、外部需求紧迫的现状,时刻关注分布式数据库发展,保持足够的技术敏感度,紧跟技术发展趋势。采取架构前置、谨慎选型、局部试点、多线布局、掌握主动、自建增强等策略,保持主动。

