- 缓存在高并发场景下的常见问题有哪些?
当数据时效性要求很高时,需要保证缓存中的数据与数据库中的保持一致,而且需要保证缓存节点和副本中的数据也保持一致,不能出现差异现象。这就比较依赖缓存的过期和更新策略。一般会在数据发生更改的时,主动更新缓存中的数据或者移除对应的缓存。
陶然 · 2018-08-14 10:05 - 斯坦福开源Weld:高效实现数据分析的端到端优化
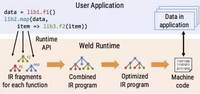
导读:Weld 是斯坦福大学 DAWN 实验室的一个开源项目,在 CIDR 2017 论文中描述了它的初始原型。Weld 用于对结合了数据科学库和函数的现有工作负载进行优化,而无需用户修改代码。我们在 VLDB 2018 论文中提出了 Weld 的自适应优化器,并得出了一些可喜的结果:通过在 Weld IR 上自动应用转换可以实现工作负载数量级的加速。
陶然 · 2018-08-14 09:32 - 公交大数据应用潜力有多大?这场比赛给你答案
近日,IBM Watson Build 2018 大中华区挑战赛随着北京和上海站的完美收官,第一轮THINK环节已经结束。睿至大数据凭借“公交线网优化和运力调优系统”顺利晋级至第二阶段。
谢涛 · 2018-08-06 15:47 - 图文教程:8步教你变身数据科学家
数据科学家是干什么的呢?哪些地方需要数据科学家?怎么样才能成为数据科学家?如果你正因为这些问题而犹豫要不要开始学习数据科学,那么我可以告诉你,成为数据科学家其实非常简单。
陶然 · 2018-08-03 13:57 - 干货 :数据分析师的完整流程与知识结构体系
作为数据分析师,无论最初的职业定位方向是技术还是业务,最终发到一定阶段后都会承担数据管理的角色。因此,一个具有较高层次的数据分析师需要具备完整的知识结构。
陶然 · 2018-08-03 09:19 - 用Python做数据科学时容易忘记的八个要点
如果你发觉自己在编程时一次又一次地查找相同的问题、概念或是语法,你不是一个人!虽然我们在StackOverflow或其他网站上查找答案是很正常的事情,但这样做确实比较花时间,也让人怀疑你是否完全理解了这门编程语言。我们现在生活的世界里,似乎有着无限的免费资源,而你只需要一次搜索即可获得。然而,这既是这个时代的幸事,也是一种诅咒。如果没能有效利用资源,而是对它们过度依赖,你就会养成不良的习惯,长期处于不利境地。
陶然 · 2018-08-01 17:31 - 数据说话:大数据处理引擎Spark与Flink比拼
自从数据处理需求超过了传统数据库能有效处理的数据量之后,Hadoop 等各种基于 MapReduce 的海量数据处理系统应运而生。从 2004 年 Google 发表 MapReduce 论文开始,经过近 10 年的发展,基于 Hadoop 开源生态或者其它相应系统的海量数据处理已经成为业界的基本需求。
陶然 · 2018-08-01 13:33 - 业界大咖齐聚武汉光谷,共论存储未来!
7月20-21日,2018全球存储半导体大会暨全球闪存技术峰会(GSS大会)在武汉光谷拉开帷幕,大会以“构建闪存新生态”为主题,针对全球闪存和存储半导体产业的生态、热点及发展道路进行了全面分析与解读,力图促进闪存与半导体产业的变革与进步,在以云计算、大数据、人工智能等技术为主导的数字信息化时代起到推动作用。
谢涛 · 2018-07-20 17:38 - 戴尔易安信数据保护方案 功能强大成本更低
尔易安信宣布推出最新的集成式数据保护应用装置(IDPA)——戴尔易安信IDPA DP4400,提供简单而强大的融合数据保护,助力中型企业进行IT转型并应对数据的蔓延和复杂性。面向中型企业的全新戴尔易安信集成式数据保护应用装置(IDPA)DP4400提供集备份、重复数据删除、复制与恢复以及基于云的灾难恢复和长期数据保留功能于一体的数据保护
陶然 · 2018-07-17 13:59 - MYSQL数据库服务的磁盘IO高问题分析与优化
压力测试过程中,因为资源使用瓶颈等问题引发的最直接的性能问题是业务交易响应时间偏大,TPS逐渐降低等。而问题定位分析通常情况下,最优先排查的是监控服务器资源利用率,例如先用TOP 或者nmon等查看CPU、内存使用情况,然后在排查IO问题,例如网络IO、磁盘IO的问题。 如果是磁盘IO问题,一般问题是SQL语法问题、MYSQL参数配置问题、服务器自身硬件瓶颈导致IOPS吞吐率问题。
陶然 · 2018-07-17 10:01 - Ceph运维告诉你分布式存储的那些“坑”
过去两年,我的主要工作都在Hadoop这个技术栈中,而最近有幸接触到了Ceph。我觉得这是一件很幸运的事,让我有机会体验另一种大型分布式存储解决方案,可以对比出HDFS与Ceph这两种几乎完全不同的存储系统分别有哪些优缺点、适合哪些场景。
陶然 · 2018-07-03 13:42 - DRDS内核技术前瞻——列式存储综述分享
本文将介绍若干个典型的列式存储数据库系统。作为完整的 OLAP 或 HTAP 数据库系统,他们大多使用了自主设计的存储方式,运行在多台机器节点上,使用网络进行通讯协作。
陶然 · 2018-06-28 11:11 - Kaggle 20G数据集强势分析“绝地求生”
吃鸡游戏自由的风格,以及配件模式的战斗方式,深受玩家的喜爱。绝地求生游戏一经推出,许多玩家由睡前一局“农药”转换成了睡前“吃一把鸡”。数据来源于Kaggle,数据量极大,包含70多万场比赛上亿条玩家的数据,大概有20G左右。到底跳哪里最安全?跳哪里一直都是一个比较纠结的问题,跳得好既可以获得充足的武器和物资,又可以提高生存概率,当然最幸运的莫过成为“天选之子”。哪里最安全,对不起,不存在滴!
陶然 · 2018-06-26 17:03 - SSD固态硬盘结构:主控算法 固件 NAND闪存
SSD固态盘是这些年在存储技术上重大进步,它带来了电脑主存储颠覆性地改变。升级SSD不仅是性能上的小幅度提升,SSD将利用具有革命性的随机访问速度、卓越的多任务处理能力、杰出的耐久度及可靠性来改变您的电脑使用体验。毫无疑问,SSD将是未来存储的主角。现将SSD组成、SSD相关技术及SSD的使用技巧等进行简单介绍,帮助更多的用户了解什么是真正的SSD。
陶然 · 2018-06-25 07:59 - 拥抱开源 Hadoop HBase存储原理结构学习
hbase是bigtable的开源山寨版本。是建立的hdfs之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统。它介于nosql和RDBMS之间,仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。主要用来存储非结构化和半结构化的松散数据。与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
陶然 · 2018-06-13 15:32 - HBase从入门到精通系列:误删数据如何抢救?
有时候我们操作数据库的时候不小心误删数据,这时候如何找回?mysql里有binlog可以帮助我们恢复数据,但是没有开binlog也没有备份就尴尬了。如果是HBase,你没有做备份误删了又如何恢复呢?
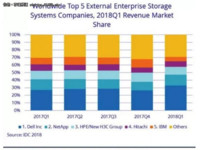
陶然 · 2018-06-12 16:51 - 全球存储市场呈井喷 2018年Q1同比猛增34%%
戴尔力压HPE、NetApp、日立和IBM,成为全球头号存储供应商。据国际数据公司(IDC)的《全球季度企业存储系统跟踪报告》显示,2018年第一季度全球企业存储系统厂商收入同比猛增34.4%%,高达130亿美元。访季度容量出货总量同比猛增79.1%%,达到98.8艾字节(EB)。2018年第一季度,直接售货给超大规模数据中心的原始设计制造商(ODM)这个群体创造的收入同比剧增80.4%%,达到31亿美元,占该季度企业存储投入总额的23.9%%。
陶然 · 2018-06-12 09:42 - 大数据分析系统Hadoop的13个开源工具分享
Hadoop是由Apache基金会开发的一个大数据分布式系统基础架构,最早版本是2003年原Yahoo!DougCutting根据Google发布的学术论文研究而来。因此,各种基于Hadoop的工具应运而生,本次为大家分享Hadoop生态系统中最常用的13个开源工具,其中包括资源调度、流计算及各种业务针对应用场景。首先,我们看资源管理相关。
陶然 · 2018-06-07 17:24 - 如何在Linux主机上 实现数据分层存储?
在存储设备中,使用分层技术,将冷热数据自动分层存放在具有不用读写性能的存储介质上,已经是很普遍的做法,比如 IBM 的 DS8K 中使用的 Easy Tier。这些功能都需要存储设备固件的支持,如何在 Linux 主机上,使用 Linux 现有的机制,实现数据的分层存储?本文主要介绍了 Linux 平台上两种不同的实现分层存储的方案。
陶然 · 2018-06-05 10:10 - “撞库”?如何加密传输和存储用户密码
近期,Github被爆出,在内部日志中记录了明文密码。虽然据说影响面很小(因为日志外部访问不到),但是网络和数据安全问题又一次被放到台面上。大多数用户的常用密码就那么几个,一旦被黑客拿到,去其他网站“撞库”,可能会造成用户的财产损失。本篇文章主要介绍如何加密传输和存储用户密码,并讲解相关原理。
陶然 · 2018-06-03 20:03