大模型训练效率是推动大模型进化关键
自2022年底ChatGPT发布,大模型一直是技术趋势热点。据爱分析调研,截至2023年9月,国产大模型数量已超百个,落地场景包含金融、能源、政务、医疗、教育等行业,大模型时代已经到来。大模型时代下,大模型训练效率将决定大模型进化速度,是大模型厂商比拼的核心。在大模型落地过程中,建设以GPU为核心的算力基础设施是讨论大模型训练效率的基本前提。
部分大模型厂商通过高性能GPU的堆叠实现“大算力”,但“大算力”不足以满足大模型时代对算力基础设施的需求,存储和网络性能将影响GPU计算效率,只有GPU、存储和网络三者高效协作,才能保证大模型训练效率。目前,高性能网络解决方案相对成熟,以InfiniBand为代表的通信技术提供了高性能计算网络。这使得过往被忽略的存储成为新焦点。为提升大模型训练效率,在大模型落地过程中,厂商要综合考虑存储性能与成本的平衡以及存储的工程化等问题。
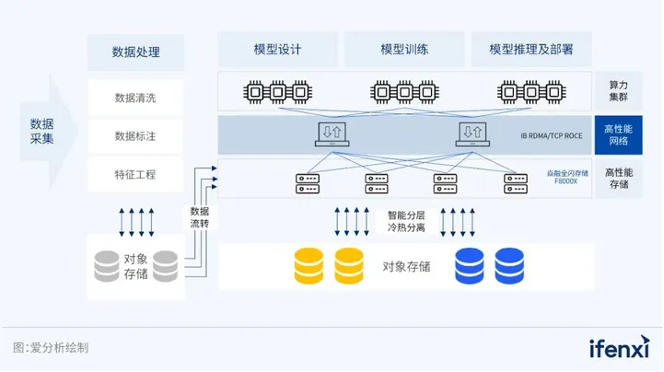
首先,数据处理效率影响大模型训练效率。数据处理效率与大模型训练效率息息相关,如数据加载过慢将降低大模型训练速度。在众多因素中,存储是影响数据处理效率的最关键因素,包括存储容量和存储性能。针对存储容量,过往AI存储场景主要是文件共享、数据备份,文件数量仅在百万到千万级别,对存储空间要求不高。而在大模型场景下,文件数量达到百亿至千亿级别,对存储空间提出更高要求。针对存储性能,大模型场景需要存储兼具高吞吐、高带宽、低延迟等特点,是“全面”高性能的要求,具体情况如下:
图1:大模型全流程对存储的需求

在数据采集和预处理阶段,大模型训练数据大部分来自互联网等公开数据集,数据体量在TB级至PB级,数据的导入和处理要求存储系统具备高吞吐。在模型设计阶段,低延迟的存储访问能加速模型参数和数据的读写,提供模型效果的实时反馈,推动大模型设计的多次迭代和优化。
在模型训练阶段,第一,模型参数量至少是百亿级别,存储需要具备高带宽,提升模型加载速度;第二,训练过程中需要读取海量小文件,不断加强模型权重训练,存储系统要能满足海量小文件处理,并支持多并行数据处理任务,具有高吞吐、高并发等特点;第三,大模型训练周期远远长于小模型,为避免因网络、硬件等因素中断训练,一般大模型训练采用Checkpoint容错机制,定期保存状态数据,这类文件庞大,要求存储具备高带宽。
在模型推理阶段,训练好的模型部署上线后要根据业务效果持续迭代,因此需要反复部署,要求存储具备高并发、高吞吐能力。综上所述,大模型对存储的要求可总结为三点:1)高带宽:满足大模型加载、Checkpoint等大文件场景的需求;2)高吞吐:满足海量小文件场景的需求;3)高并发、低延时:满足并行数据处理、多用户推理场景下的高并发、低延时需求。
其次,模型规模激增,数据存储需要平衡成本和性能。随着模型参数增大,训练数据集的规模呈现出指数级增长,存储成本随之大幅增加。以OpenAI为例, GPT2.0的模型参数是15亿,训练文本数据为40GB;GPT3.0的模型参数是1750亿,训练数据量570GB。如何控制存储成本是企业用户和大模型厂商必须解决的难点,需要对整体存储方案进行优化,在满足高性能存储的前提下,解决大模型参数增长带来的存储成本问题。
第三,大模型落地带来大量工程化工作。海量数据在各环节中的存储格式和存储系统都不相同,如何加速数据在各环节的自动流转需要进行大量优化工作;同时,在大模型落地不同阶段有数据科学家、数据工程师、软件开发员等多种角色参与,如何保护数据安全、设置数据访问权限等问题,也需要在存储系统中一并解决。
全闪分布式并行文件存储是实现大模型训练加速的“共识”方案
要满足大模型落地的种种要求,选择适合的存储技术方案尤为关键,从存储介质、存储架构等方面分析,全闪分布式并行文件存储是最 优方案,并已在市场中初步形成共识。
图2:全闪分布式并行文件存储是大模型加速的解决方案

从存储介质角度,大模型高性能存储要求存储介质迭代,“全闪”成必选项。当前市场存储介质主要采用传统硬盘(HDD)和固态硬盘(SSD)两类。传统硬盘吞吐量较低,数据读写速度有限,并且传统硬盘使用旋转磁盘和机械臂定位数据,会带来较高的访问延迟,难以满足大模型训练对高性能的要求。固态硬盘没有传统硬盘的旋转盘片、机械臂等机械硬件,使用闪存芯片存储数据,兼具高吞吐、低延迟、高并发等特性,更能适应大模型参数和数据规模指数增长场景下对高性能存储的要求。
从存储架构角度,分布式并行文件系统更能满足大文件、小文件全流程高带宽、高吞吐以及低延迟需求。大模型训练的并行访问要求高带宽。传统NFS文件系统适用于低并发用户对小数据集的访问场景,但在用户并发数大或数据集太大时,NFS服务器会成为IO路由瓶颈,限制系统性能。而并行文件系统能支持多客户端直接访问所有存储节点,从根本上消除这个瓶颈,更适用于对并发要求高的大模型训练场景。
另外,为保证数据一致性,大模型需采用有元数据服务(MDS)的存储架构。传统中心对称的元数据架构会限制系统伸缩性,在大模型高并发、高性能的场景下,全对称元数据架构成为首选。目前,全对称架构重点解决MDS规模和性能匹配问题,尤其海量小文件处理场景中的性能稳定性。
焱融科技解决方案具备高性能、高存储ROI和易用性等特点
从国内高性能存储市场发展来看,国内泛AI领域对高性能存储需求明确,传统行业“上云”趋势明显,叠加近两年大模型的广泛落地,共同驱动高性能存储市场快速发展。当前高性能存储的市场参与者除华为、新华三等传统厂商外,还有以焱融科技为代表的专注高性能存储的厂商。
焱融科技自成立起即定位高性能存储,在对存储需求和存储技术的深刻洞察下,提前布局全闪分布式存储。在存储需求方面,焱融科技持续聚焦AI、HPC场景,在不到十年的时间中,已经在基因测序、自动驾驶、量化分析,多模态AI,语音AI,数字人等泛AI领域积累了丰富的客户资源和实践经验,因此提前预见到泛AI领域对高性能存储的需求趋势。在技术方面,焱融科技观察到全闪存储在企业的应用场景日益广泛,全闪存储对机械硬盘的替代趋势明显。
于是,2022年5月,焱融科技推出企业级全闪分布式文件存储一体机追光F8000X,并适配主流NVIDIA H800的GPU 服务器,其“单节点4卡”解决方案支持800Gbps InfiniBand带宽接入,可灵活适应NVIDIA H800 PCIe 5.0计算平台和PCIe 4.0硬件平台。
图3:大模型场景下全闪存储F8000X解决方案
根据爱分析的调研,焱融科技的全闪分布式文件存储一体机追光F8000X解决方案具备以下三个特点。
第一,追光F8000X高性能的特质,充分满足大模型训练和推理的存储需求。一方面,追光F8000X分布式并行文件系统兼具大文件高带宽和海量小文件高吞吐能力特点,另一方面,焱融科技支持NVIDIA®Magnum IO GPUDirect®技术,深度优化数据 IO路径,能够显著降低GPU服务器内的CPU占用率,增加存储吞吐能力并减少延迟。大文件场景,追光F8000X将元数据和数据存储分离,采用并行文件系统,有效减少大文件操作对MDS更新频率,为大文件操作提供高带宽,提升大文件的并发访问性能。同时,采用预读 Readahead技术,提升顺序数据读性能,有效减少存储和应用程序的I/O 等待时间,缩减网络和磁盘的开销,加速AI大模型训练的效率。海量小文件场景,元数据管理性能是核心瓶颈。为解决这一问题,追光F8000X通过扩展元数据节点的方式,实现元数据的分布存储和负载均衡,可提供百万级的IOPS及高吞吐能力,支持百亿级别的文件数量,整体提升了元数据的检索性能。同时,焱融科技还基于元数据管理技术,减少跨网络和磁盘访问开销,避免海量小文件内存不足带来的业务卡顿,系统性能获得进一步提升。
第二,通过智能分层,追光F8000X能降低存储总TCO,提升存储ROI。在服务泛AI客户过程中,焱融科技发现,对大多数进行AI模型训练的客户而言,数据具有阶段性热点访问的特点,超过一定时间后,80%以上的数据逐步趋冷。因此,如何实现统一的数据管理,根据数据访问热度,对冷、热数据进行全局调度,达到数据存储和管理的最 佳效率 ,是降低数据存储成本的关键。焱融科技存储系统提供智能分层功能,客户可根据策略定义冷热数据层,冷数据自动流动至本地或公有云对象存储中,向上仍然为业务提供标准的文件访问接口,数据在冷热数据层之间流动对业务完全透明。在保证热层数据高性能的同时,降低了数据存储成本,提升了数据可靠性。
第三,焱融科技存储系统具备高易用性,降低工程化成本。大模型落地全流程中,不同阶段往往采取不同的存储类型,如数据处理阶段采用对象存储,大模型训练阶段采用高性能的全闪分布式文件存储。过往训练数据在不同阶段的流动往往通过手动复制,等待时间较久。焱融科技提供了Dataload智能数据加载功能,打通对象存储与文件存储,一键实现跨存储空间数据加载。如一键将公有云上的数据加载到全闪存储中进行训练,训练完成后又一键导出到对象存储中。
焱融科技联合智谱AI构建高速大模型训练平台
目前焱融科技全闪分布式文件存储一体机已经与多家大模型厂商达成合作,其中,与北京智谱华章科技有限公司(简称“智谱AI”)的合作极具代表性。
智谱AI成立于2019年,于2022年推出千亿参数大模型GLB-130B,并在2023年累计完成25亿融资,是国内大模型市场的第一梯队厂商。此前,智谱AI训练平台的存储方案以混闪为主,尝试通过堆叠存储节点满足空间容量和高并发带宽访问需求,但这种方式造成存储空间严重浪费和存储成本的急剧增长,在数据体量持续增长的情况下不可持续。因此,智谱AI希望采购新的存储方案,同时满足高性能存储和成本可控。智谱AI经过多方调研,在综合考量技术先进性、性能指标、成功案例等因素后,与焱融科技达成合作,有效解决了在数十亿文件场景下,元数据操作性能和小文件访问性能衰减等问题,极大提升了 AI 业务的计算分析性能,降低了整体 TCO 。

