如何优雅地使用Redis之位图操作
作者:黄泽杰 来源:微信公众号Java架构沉思录
原文链接: https://mp.weixin.qq.com/s/DBqBcBoVtZhH8rMUwXubow
在进入今天的主题前,先简单地解释下Redis中的位图到底是什么。Redis官方文档对于位图的介绍如下:
位图不是一个真实的数据类型,而是定义在字符串类型上的面向位的操作的集合。由于字符串类型是二进制安全的二进制大对象,并且最大长度是 512MB,适合于设置 2^32个不同的位。
位操作分为两组:常量时间单个位的操作,像设置一个位为 1 或者 0,或者获取该位的值。对一组位的操作,例如计算指定范围位的置位数量。
位图的最大优势是有时是一种非常显著的节省空间来存储信息的方式。例如,在一个系统中,不同用户由递增的用户 ID 来表示,可以使用 512MB 的内存来表示 400 万用户的单个位信息(例如他们是否需要接收信件)。

简而言之,位图操作是用来操作比特位的,其优点是节省内存空间。为什么可以节省内存空间呢?假如我们需要存储100万个用户的登录状态,使用位图的话最少只需要100万个比特位(比特位1表示登录,比特位0表示未登录)就可以存储了,而如果以字符串的形式存储,比如说以userId为key,是否登录(字符串“1”表示登录,字符串“0”表示未登录)为value进行存储的话,就需要存储100万个字符串了,相比之下使用位图存储占用的空间要小得多,这就是位图存储的优势。
位图常用操作
位图的常用操作如下:
·setbit
设置特定key对应的比特位的值。
·getbit
获取特定key对应的比特位的值。
·bitcount
统计给定key对应的字符串比特位为1的数量。
使用位图存储用户登录状态
位图的常见应用是用来存储状态值,比如存储用户的登录状态。
假设我们现在有一个需求,需要记录用户注册以来每天的登录状态,那么我们就可以以用户id为key,然后以日期或者日期的偏移量作为下标,将登录状态存储到对应的比特位中,这样就可以很方便地获取用户某一天的登录状态了。
接下来看代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | public class UserLoginStatusService { private static final String host="111.111.111.111"; private static final int port=6379; private static final Jedis jedis=new Jedis(host,port); //日期的初始值(也可以理解为用户的注册时间), //下文需要使用日期的偏移量作为redis位图的offset, //因此需要将要保存登录状态的日期减去该初始日期。 //这里使用了Java 8的新日期API private static final LocalDate beginDate=LocalDate.of(2018,1,1); static { jedis.connect(); } public void setLoginStatus(String userId, LocalDate date,boolean isLogin){ long offset = getDateDuration(beginDate, date); jedis.setbit(userId,offset,isLogin); } public boolean getLoginStatus(String userId,LocalDate date){ long offset = getDateDuration(beginDate, date); return jedis.getbit(userId,offset); } private long getDateDuration(LocalDate start ,LocalDate end){ return start.until(end, ChronoUnit.DAYS); } public static void main(String[] args) { UserLoginStatusService userLoginStatusService=new UserLoginStatusService(); String userId="user_1"; LocalDate today = LocalDate.now(); userLoginStatusService.setLoginStatus(userId,today,true); boolean todayLoginStatus = userLoginStatusService.getLoginStatus(userId, today); System.out.println(String.format("The loginStatus of %s in %s is %s",userId,today,todayLoginStatus)); LocalDate yesterday = LocalDate.now().minusDays(1); boolean yesterdayLoginStatus = userLoginStatusService.getLoginStatus(userId, yesterday); System.out.println(String.format("The loginStatus of %s in %s is %s",userId,yesterday,yesterdayLoginStatus)); } } |
代码不复杂,我们在main方法中设置当天的登录状态为true,然后分别查出当天的登录状态和昨天的登录状态,由于redis位图的比特位默认是0,所以该代码的正确输出应该是今天已登录,昨天未登录,我们运行一次看看结果。

从程序运行结果来看,Redis的位图确实满足了我们的需求,且兼有节省存储空间的优点。
使用位图统计登录天数
接下来我们有一个新需求,就是统计某个用户注册后前10天的登录天数,Redis中有个bitcount命令,可以统计某个字符串中的比特位为1的数量,其还有2个参数start和end,表示要统计的范围,咋一看好像可以用来实现我们这个需求,但是这里有一个坑需要注意下,bitcount命令的start和end参数指的是字节的索引,而不是比特位的索引,而我们如果要使用位图来统计某个用户注册后前10天的登录天数的话,需要统计的是比特位索引从0到9的比特值为1的数量,所以直接使用bitcount命令显然是无法满足要求的。那么假如说我们一定要用位图来存储登录状态呢,应该咋办呢?其实办法还是有的。我们可以先拿到比特位索引从0到9所在的字节数组,再将该字节数组解析成二进制形式,进而统计出比特位索引从0到9比特值为1的数量。
要拿到比特位索引所在的字节在字节数组中的下标比较简单,只要将比特位索引除以8(一个字节包含8个比特位)再向下取整就行了。接下来就是使用redis的getrange命令来截取字节数组了。
拿到了字节数组,接下来就是解析字节数组,统计其中比特值为1的数量了。我们先从最简单的单个字节说起,假设一个字节的各个比特位的值如下:
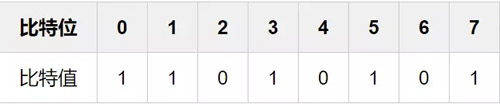
我们设比特位索引为index,假如我们要计算比特位为7的比特值,只需要将原值直接跟1进行与运算就行了。要计算比特位为6的比特值,只需要将原值右移1位,再跟1进行与运算。以此类推,要计算第index位的比特值,只需要先右移(7-index)位,再跟1进行与运算即可。
只要能够统计出截取出来的的字节数组中比特位的值为1的数量,接下来再减去不包含在对应比特索引中的比特值为1的数量,即可统计出给定的比特索引范围内比特值为1的数量。
这么说有点拗口,我们以上述例子为例进行讲解吧。我们要统计出用户注册后前10天的登录天数,如果用位图存储用户登录状态,位图中的索引为注册天数的话,那么我们需要统计比特索引从0到9的比特值为1的数量,才能计算出该用户注册后前10天的登录天数。
我们先计算出比特索引从0到9包含在哪一段字节数组中,前面说了,只需要将对应的索引除以8,再向下取整就行了。从而可以得知比特位索引从0到9对应的是下标从0到1的字节数组。
接下来使用getrange命令截取该字节数组,假设其值如下:
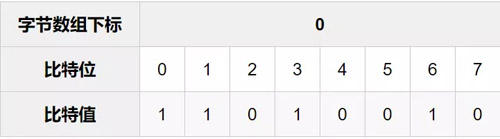
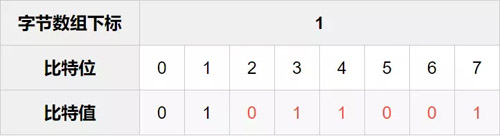
假设比特索引0到9对应的字节数组的比特值情况如上所示,我们需要统计的是第一个字节(下标为0)中的0到7位中比特值为1的数量,再加上第二个字节(下标为1)中的第0到1位中比特值为1的数量。加起来刚好10位,也就是对应用户注册前10天的登录天数。当然我们也可以统计出这2个字节中的比特值为1的总数,再减去第二个字节的从2到7位(上述表格标红的地方)中比特值为1的数量,也可统计出该用户注册后前10天的登录天数。本文用的是第二种方法。
接下来上代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | private static final int BIT_AMOUNT_IN_ONE_BYTE =8; private Jedis jedis; public int bitCountByBitIndex(String key, long startBitIndex, long endBitIndex) { int startByteIndex = getByteIndexInTheBytes(startBitIndex); int endByteIndex = getByteIndexInTheBytes(endBitIndex); byte[] bytes = jedis.getrange(key.getBytes(), startByteIndex, endByteIndex); int totalBitInBytes = getTotalBitInBytes(bytes); int startBitIndexInFirstByte = getBitIndexInTheByte(startBitIndex); int endBitIndexInLastByte = getBitIndexInTheByte(endBitIndex); byte firstByte = bytes[0]; byte lastByte = bytes[bytes.length-1]; for(int i=7;i>(BIT_AMOUNT_IN_ONE_BYTE-1-startBitIndexInFirstByte);i--){ if(((firstByte>>i)&1)==1){ totalBitInBytes--; } } for(int i=0;i<(BIT_AMOUNT_IN_ONE_BYTE-1-endBitIndexInLastByte);i++){ if(((lastByte>>i)&1)==1){ totalBitInBytes--; } } return totalBitInBytes; } private int getTotalBitInBytes(byte[] bytes){ int count=0; for(byte b:bytes){ for(int i = 0; i< BIT_AMOUNT_IN_ONE_BYTE; i++){ if(((b>>i)&1)==1){ count++; } } } return count; } private int getByteIndexInTheBytes(long offset){ return (int) offset/ BIT_AMOUNT_IN_ONE_BYTE; } private int getBitIndexInTheByte(long offset){ return (int)(offset-offset/ BIT_AMOUNT_IN_ONE_BYTE * BIT_AMOUNT_IN_ONE_BYTE); } |
代码就不注释了,整体思路已经在上面讲解了。
当然要实现本文所述的功能,也不一定非要这么做,还是有其他的方案的。比如:可以将放入位图的offset统一乘以8(一个字节占8比特),这样一来就可以直接用redis的bitcount来统计对应索引范围内的比特值为1的数量了,当然这种方案的缺点也相当明显,就是浪费内存,因为原先只需要1比特存储的数据,现在需要8比特存储,所以这种方案不能很好地利用位图索引节省存储空间的特点。

